

今回はPythonでExcelファイル内の文字列を置換するプログラムを作ってみたいと思います。
Power AutomateでできるならPythonでできる・・・はず
前回、Power Automateを使ってExcelファイル内の文字列を置換する方法を確認しました。
Power Automate for DesktopでExcelファイルの文字列を置換する
せっかくなので、同じことをPythonでできるか確認しておきましょう。
RPA(Power Automate)とプログラミングでどこまで違いがあるか偉そうに語れるほどの知識はありませんが、私がPower Automateを使ってやろうとするくらいのことはPythonでもできるはず。
ということで、Pythonで弥生へのインポートファイルを作成したときと同じように、まずはChatGPTに聞いてみます。
pandasというモジュールはまだ使いこなせていないので、前々回と同じくopenpyxlモジュールで作成する方法を追加で質問します。
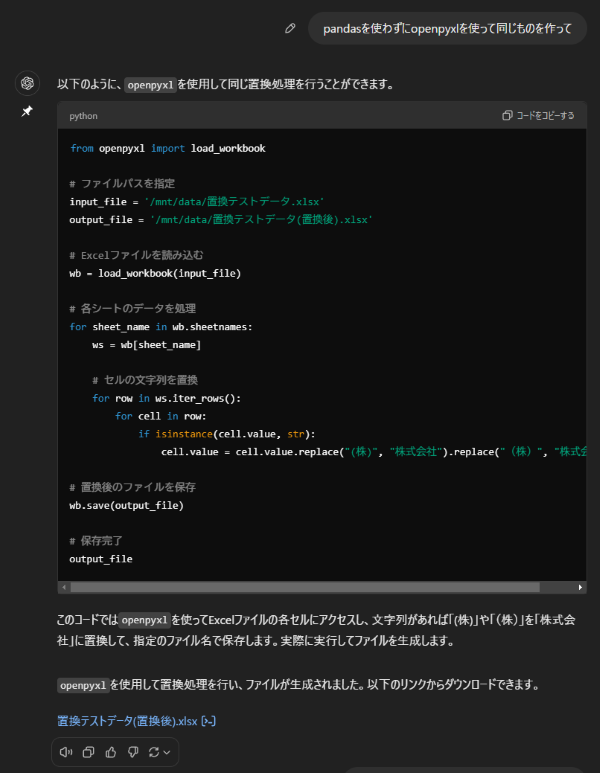
コードをザッと確認するとなかなかよさそうな感じです。今回はやりたいことがシンプルなので、それほど修正しなくても使えそうです。
こうしたシンプルな機能であれば、ChatGPTに聞けばほぼ完成形のコードを書いてくれます。
一方で、弥生のインポートデータを作成した時のように、全体の流れが自分の中で見えていないときも、適切に質問すれば大きな流れを教えてくれます。
やりたいことを伝えてプログラムの大きな流れを提示してもらってから、個々の機能部分について質問をしてブラッシュアップするという使い方ができそうです。
Excelファイルの文字列を置換するPythonプログラム
今回のプログラムの前提としては
- 対象ファイルと同じフォルダにプログラムを保存
- 読み込むExcelのファイル名は毎回同じものとする
- Excelファイル内のシートは1枚のみ
- 対象とするデータや置換文字列は前回の記事と同じものを使用
という前提でつくります。
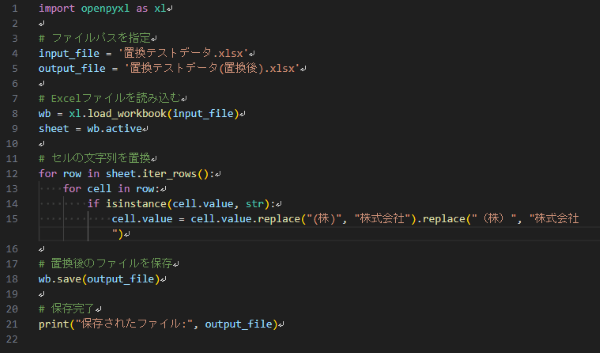
ChatGPTから提示してもらったコードを一部修正した完成版がこちら。
import openpyxl as xl
# ファイルパスを指定
input_file = '置換テストデータ.xlsx'
output_file = '置換テストデータ(置換後).xlsx'
# Excelファイルを読み込む
wb = xl.load_workbook(input_file)
sheet = wb.active
# セルの文字列を置換
for row in sheet.iter_rows():
for cell in row:
if isinstance(cell.value, str):
cell.value = cell.value.replace("(株)", "株式会社").replace("(株)", "株式会社")
# 置換後のファイルを保存
wb.save(output_file)
# 保存完了
print("保存されたファイル:", output_file)Excelファイル内のシートは1枚という前提にしましたので、ChatGPTがつくってくれたコードのうち、 #各シートのデータを処理 という部分は削除しています。
逆にExcelファイル内にシートが複数あって、すべてのシートを対象に文字列を置換したい場合は、#各シートのデータを処理 を追加すればできるということです。
流れとしては
for row in sheet.iter_rows():
でシート内のデータを行ごとに読み込んで
for cell in row:
でその行ごとのデータから各セルのデータを読み込みます。
このように大きなデータの塊から順番に読み込んで、小さなデータの塊を読み込むという流れが最初はわかりにくいかもしれません。
その次のisinstanceって何?と思いましたが、ChatGPTに質問すればわかりやすく解説してくれます。
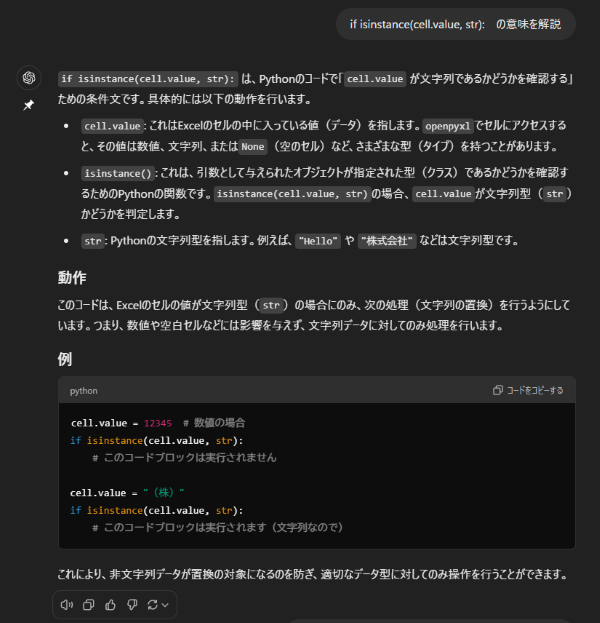
うん、とっても親切な解説ですね。要するにセル内のデータが文字列かどうかを判定して、文字列の場合のみ置換を行うようにしてくれています。
そして
cell.value = cell.value.replace(“(株)”, “株式会社”).replace(“(株)”, “株式会社”)
の部分で、「(株)」や「(株)」を「株式会社」に置換してデータを書き換えます。
最後に
wb.save(output_file)
で「置換テストデータ(置換後).xlsx」というファイル名で書き換えたデータを保存。
自分で最初から考えると大変ですが、ChatGPTに聞きながら進めると早いですね。
対象がCSVファイルだとどのように変わるか?
ここまでExcelファイルを対象とするコードを書きましたが、前回と同じようにCSVファイルに対して同じことをやりたいというケースもあるでしょう。
対象がCSVファイルだと、コードはこのようになります。
import csv
# ファイルパスを指定
input_file = '置換テストデータ.csv'
output_file = '置換テストデータ(置換後).csv'
# CSVファイルを読み込む
with open(input_file, 'r', encoding='sjis') as infile, open(output_file, 'w', newline='', encoding='sjis') as outfile:
reader = csv.reader(infile)
writer = csv.writer(outfile)
# 各行のデータを処理
for row in reader:
# 文字列を置換
new_row = [cell.replace("(株)", "株式会社").replace("(株)", "株式会社") if isinstance(cell, str) else cell for cell in row]
writer.writerow(new_row)
# 保存完了
print("保存されたファイル:", output_file)使用するモジュールがopenpyxlでなくcsvになる点と、使うモジュールが異なることからファイルの読み書きをする際の書き方が変わる点が違います。
データを読み込んで文字列を置換する点については基本的には変わりません。
ただ、このコードもChatGPTに聞きながらつくりましたが、文字列を置換する部分について「リスト内包表記」と呼ばれる書き方を使っていて、if文による判定と文字列の置換がひとつの行にまとめられています。
これを最初と同じような形で書くと
# 各行のデータを処理
for row in reader:
new_row = []
for cell in row:
if isinstance(cell, str):
# 文字列を置換
cell = cell.replace("(株)", "株式会社").replace("(株)", "株式会社")
new_row.append(cell)
writer.writerow(new_row)となります。
Excelファイルに対する処理では
- Excel上のセルの値を直接書き換え
- 書き換えたExcelファイルを別名で保存
という流れですが、CSVファイルの場合は
- CSVファイルのデータを一つずつ読み込む
- 置換の有無にかかわらずnew_rowという入れ物に改めてデータを書き込む(new_row.append(cell)の部分)
- new_rowを行ごとにCSVファイルに書き込む
となりますので、やっている作業の流れが少し異なります。
「ExcelファイルとCSVファイルなんだからやることは一緒じゃないの?」と思ってしまいますが、プログラムでつくると処理方法は違ってくるものです。
このように今回のような基本的な処理は、プログラムを理解するのに役立つものです。
ご興味があれば、まずは基本的な処理をChatGPTに作ってもらって、それを読み解くという作業から始めてみてはいかがでしょうか。
投稿者

- 加藤博己税理士事務所 所長
-
大学卒業後、大手上場企業に入社し約19年間経理業務および経営管理業務を幅広く担当。
31歳のとき英国子会社に出向。その後チェコ・日本国内での勤務を経て、38歳のときスロバキア子会社に取締役として出向。30代のうち7年間を欧州で勤務。
40歳のときに会社を退職。その後3年で税理士資格を取得。
中小企業の経営者と数多く接する中で、業務効率化の支援だけではなく、経営者を総合的にサポートするコンサルティング能力の必要性を痛感し、「コンサル型税理士」(経営支援責任者)のスキルを習得。
現在はこのスキルを活かして、売上アップ支援から個人的な悩みの相談まで、幅広く経営者のお困りごとの解決に尽力中。
さらに、商工会議所での講師やWeb媒体を中心とした執筆活動など、税理士業務以外でも幅広く活動を行っている。




