


PDFは扱いやすいファイルではありますが、通常は開いていない状態で内容を検索できません。今回はPDFファイルの検索について検討してみましょう。
PDFファイルの文字列を選択できない
PDFファイルの中の一部のデータをコピペしたいことってありませんか?
そんな時にマウスで範囲選択できるケースとできないケースがあります。文字を選択しようとすると、この図のようになってしまう状態です。

ちなみにこの図のPDFファイルは、前回のブログ記事の一部をWordに貼付けて紙に印刷した後に、OCR処理なしでスキャンしたものです。
有料版のAcrobatにおいては、この状態でPDF内の文字列を検索しようとしても、次のように検索できない旨のメッセージが表示されます。
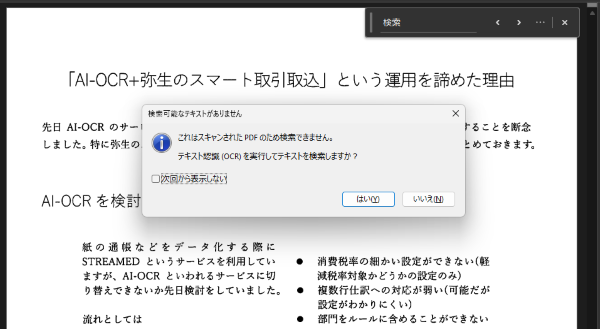
このようなケースで文書内の文字列を検索できるようにしたい場合は、先ほどのメッセージにしたがってテキスト認識(OCR)を行う必要があります。
もしくはAcrobatの「すべてのツール」から「スキャンとOCR」を選んで、「テキスト認識」の中の「このファイル」を選択しても同じようにOCR処理が実行されます。
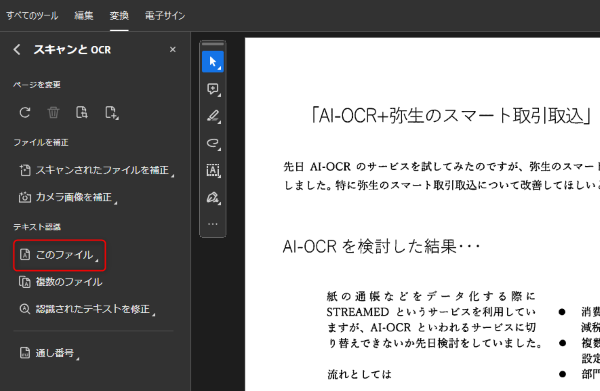
※Acrobatの無料お試し版でも同じことはできるようですが、使用期限がありますので永続的に使用するには有料版が必要となります。
PDFや画像の文章を文字起こし(テキスト化)できるツールと手順
EvernoteとNotionのPDF検索の違い
内容を探したいPDFファイルがわかっていて、その中から必要な文字列を検索するのであれば先ほどの方法で十分対応できます。
ところが実際には
「どのPDFファイルに必要な情報があるのかわからないので、複数のPDFファイルをまとめて検索したい」
というケースは起こりえます。
こうしたケースで使える方法のひとつがEvernoteの有料版です。
Evernote内にPDFファイルを保存して検索を行うと、PDFファイル内の文字列も含めてまとめて検索してくれます。
この機能、あまり意識せずに使っていましたが、Evernote内を検索すると確かにPDFファイル内の文字も検索してくれます。
Evernoteは使いにくくなった面が多々ありますが、この点に関してはかなり便利な機能です。
大量のPDFファイルを中身まで検索できる状態で管理したいというニーズがある場合は、Evernoteの有料版も選択肢のひとつとなるでしょう。
その一方でEvernoteと比較されることの多いNotionですが、私が調べた限りではPDF内の検索には対応していないようです。
仕様について書いたページは見つけられなかったのですが、テキスト認識した後のPDFファイルであっても、中身について検索できないと思われます。
そのためNotion内にPDFファイルを保存しても、そのPDFファイルの内容をあとから検索で見つけることができません。
NotionAIの一機能であるNotionQ&Aについても、PDFファイルの内容を元に回答する機能は今のところなさそうです。
あとで検索できるようにするためには、PDFファイルを保存した際に
- 簡単な要約
- タグ
- キーワード
などをつけておいた方がよいということになります。
ただ、PDFファイルを保存する度にこうした作業を行うのは面倒ですから、続けられるかどうかという問題は残ります。
NotionでPDFファイルを検索したい場合の対処方
NotionでPDFファイルを保存する際に、考えられる運用のひとつが
PDFファイルと一緒にファイル内のテキストを同じページにとりあえず貼付けておく
という方法です。
これであればテキストファイルが検索対象となりますので、あとから検索で探すことができます。
テキスト認識(OCR処理)がされていないPDFファイルについては、最初にご紹介した方法などでOCR処理をかければ簡単にテキストをコピペできます。
もしNotionAIを契約されているのであれば、貼り付けたあとに文章を要約してもらって、その文章だけ残しておくという方法も考えられます。
理想を言えば、PDF内の情報も検索できるようにしてもらえるとありがたいのですが、運用でカバーする際のやり方のひとつとして参考にしていただければ・・・
とこんなことを考えていたら、PDFファイルをNotionのページとしてインポートする機能が追加されていました。

Notionのページで「/pdf」と入力すると、従来はなかった
「インポート PDF」
というメニューが表示されます。
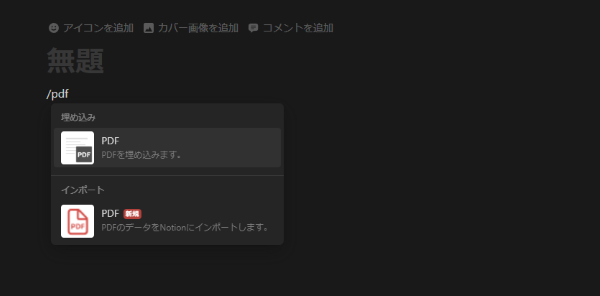
「埋め込み PDF」を使うと、NotionのページにPDFが埋め込まれるだけであり、検索やQ&A機能の対象とはなりません。
その一方で「インポート PDF」を使うとPDFファイルがNotionのページとしてインポートされますので、検索やQ&A機能の対象とすることができます。
ちなみにこの機能を早速試してみたところ、現状では次のような挙動になっています。
| ファイルの種類 | インポート結果 |
| OCR処理していないPDFファイル | 埋め込みと同じ状態でインポート |
| OCR処理後のPDFファイル | 埋め込みと同じ状態でインポート |
| Wordから直接PDFファイルにしたもの | Notionのページとしてインポート |
最初の2つについてはこのような状態になり、想定していたものとはなっていません。

その一方でWordから直接PDFして保存したファイルについては、Notionのページとして読み込まれましたが、段組を無視してインポートされているため文章としては崩れてしまっています。

期待したレベルにはまだ達していませんが、今後の改善に期待といったところでしょうか。
今回の記事、PDFファイルの内容を検索したいという方の参考になれば幸いです。
投稿者

- 加藤博己税理士事務所 所長
-
大学卒業後、大手上場企業に入社し約19年間経理業務および経営管理業務を幅広く担当。
31歳のとき英国子会社に出向。その後チェコ・日本国内での勤務を経て、38歳のときスロバキア子会社に取締役として出向。30代のうち7年間を欧州で勤務。
40歳のときに会社を退職。その後3年で税理士資格を取得。
中小企業の経営者と数多く接する中で、業務効率化の支援だけではなく、経営者を総合的にサポートするコンサルティング能力の必要性を痛感し、「コンサル型税理士」(経営支援責任者)のスキルを習得。
現在はこのスキルを活かして、売上アップ支援から個人的な悩みの相談まで、幅広く経営者のお困りごとの解決に尽力中。
さらに、商工会議所での講師やWeb媒体を中心とした執筆活動など、税理士業務以外でも幅広く活動を行っている。
最新の投稿
 仕事術・勉強法2025年7月10日「対応の早さ」は作れるし、それだけで違いになる
仕事術・勉強法2025年7月10日「対応の早さ」は作れるし、それだけで違いになる- ブログ・HP2025年7月6日「仕事やめる時、自分のドメインどうしようか問題」について
- 税理士2025年7月3日法人の事業承継について、街の税理士目線で考えてみる
- 経営管理2025年6月29日月次決算の早期化が大事な理由とその対策




